J’ai récemment eu l’opportunité de travailler sur un système d’agent IA ayant accès à des données privées.
Pour y arriver l’approche était plutôt simple: mettre en place une base de données vectorielle et récupérer les données nécessaires avec du RAG.
Easy n’est ce pas?
Pour cela, j’ai étudié 4 solutions de base de données vectorielles.
- Google Cloud Vertex AI RAG engine
- Google Cloud Vector Search
- ChromaDB
- Milvus
Dans cette série, nous allons explorer chaque technologie, voir les avantages et les inconvénients et apprendre.
Scénario
Nous avons plusieurs documentations, code que nous aimerons utiliser pour augmenter les connaissances de nos agents IA.
Les données sont sous format Markdown, Code (json, terraform, yaml, python).
Nous allons donc faire du RAG.
Le Retrieval Augmented Generation (RAG) est une technique qui améliore les LLM en les connectant à des sources de données externes. En combinant les capacités de génération de modèles comme Gemini avec des mécanismes de recherche d’information précis, le RAG permet aux systèmes d’IA de produire des réponses plus exactes et mieux contextualisées.
RAG Engine: le choix le plus simple
Bon le titre est assez clair. C’est la première approche que j’ai essayé et c’est sans doute le plus simple.
RAG Engine c’est quoi ?
Ce service fait partie de l’arsenal de service ML/IA proposé par Google Cloud sous Vertex AI.
RAG engine est un service manager qui permet d’ingérer des documents, de les indexer et de faire la recherche automatiquement quand un utilisateur pose une question. Le modèle récupère alors les passages les plus pertinents et s’en sert pour produire une réponse plus fiable.
Rag Engine va alors nous faciliter la gestion de base de connaissance et nous simplifier les requêtes de recherches.
Le moteur RAG de Vertex AI fonctionne avec des index appelé corpus.
Ce schéma résume un peu le fonctionnement.
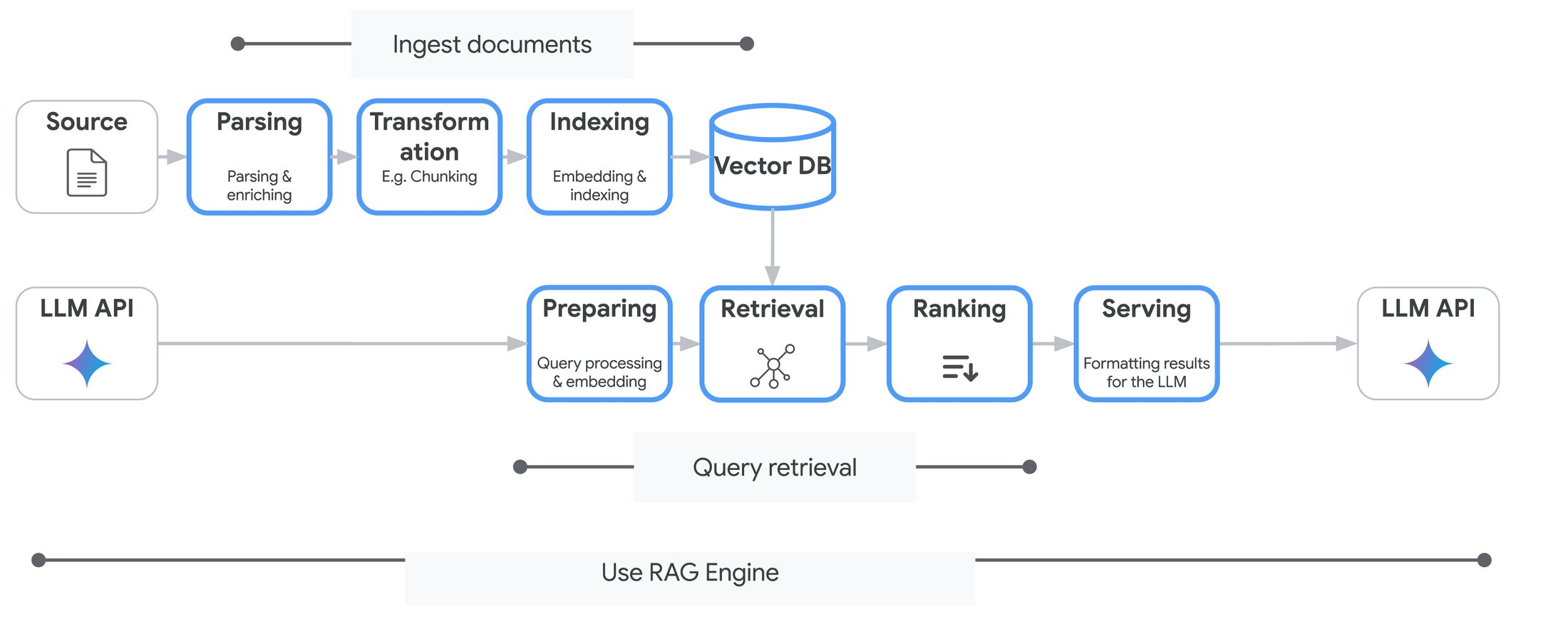
Dans notre cas, va falloir qu’on commence par le parsing. Avec le type de document que nous avons (code, markdown) le plus simple c’est de les convertir en fichier texte (.txt. en changeant les extensions).
Types de documents supportés sont :
| Type de fichier | Limite de taille du fichier |
|---|---|
| HTML | 10 Mo |
| JSON | 10 Mo |
| Markdown | 10 Mo |
| Présentations Microsoft PowerPoint (fichier PPTX) | 10 Mo |
| Documents Microsoft Word (fichier DOCX) | 50 Mo |
| Fichier PDF | 50 Mo |
| Fichier texte | 10 Mo |
Voir plus https://docs.cloud.google.com/vertex-ai/generative-ai/docs/rag-engine/supported-documents
Des types de fichiers supplémentaires sont pris en charge par un parseur
LLM https://docs.cloud.google.com/vertex-ai/generative-ai/docs/rag-engine/llm-parser
Nous aurons juste a mettre nos documents sur Google Cloud Storage pour l’ingestion depuis les buckets.
Il est aussi possible de passer par plusieurs autres sources comme Google Drive, Slack ou plus.
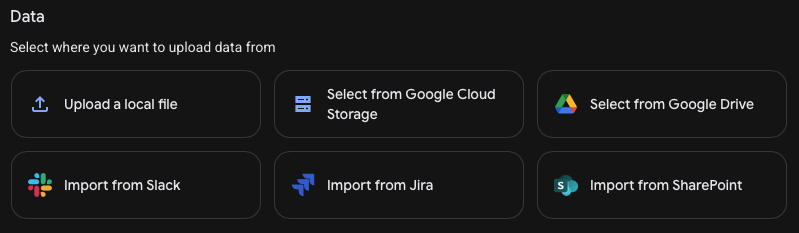
Etape 3: Transformation:
Après l’ingestion d’un document, Vertex AI RAG Engine exécute une série de transformations pour préparer les données à l’indexation comme le chunking.
Le découpage/chunking est une technique fondamentale qui améliore l'efficacité, la précision et l'évolutivité des applications d'IA. En structurant les données en segments bien définis, les modèles d'IA peuvent extraire et traiter l'information plus efficacement, ce qui se traduit par de meilleures performances, des coûts réduits et une expérience utilisateur optimisée.
Nous pouvons ajuster ce processus selon vos besoins à l’aide des paramètres suivants:
chunk_size: détermine la taille de chaque segment. La valeur par défaut est 1 024 tokens.chunk_overlap: taille du chevauchement partiel des chunks pour améliorer la pertinence et la qualité de la récupération d’information. 256 tokens par defaut
Etape 4: Embedding
L'embedding est un moyen de représenter des objets comme du texte, des images et de l'audio sous forme de points dans un espace vectoriel continu où les emplacements de ces points dans l'espace sont sémantiquement significatifs pour les algorithmes d'apprentissage automatique (ML).
Pour cette étape avec RAG Engine, il faudra sélectionner l’embedding qui va mieux avec les données, voir https://docs.cloud.google.com/vertex-ai/generative-ai/docs/rag-engine/use-embedding-models
Moi je choisi text-embedding-005 , Il est recommandé de l'utiliser avec un corpus RAG Engine.
embeddings_model = rag.RagEmbeddingModelConfig(
vertex_prediction_endpoint=rag.VertexPredictionEndpoint(
model="text-embedding-005",
),
)
Etape 5: Stockage en base de donnée vectorielle
Vertex AI RAG Engine propose par défaut RagManagedDb. C’est une base de données vectorielle entièrement gérée et prête pour l’entreprise. Elle ne nécessite aucune configuration ni maintenance, ce qui permet de se concentrer directement sur le développement d’applications RAG
Plusieurs options sont disponibles selon les besoins :
- Vector Search (Vertex AI) : solution optimisée pour les workloads de machine learning et intégrée à l’écosystème Google Cloud.
- Vertex AI Feature Store : adapté aux architectures utilisant déjà BigQuery et la gestion de features ML.
- Weaviate : base vectorielle open source, flexible et modulable, avec support de différents types de données et de plusieurs clouds.
- Pinecone : base vectorielle cloud native spécialisée dans la recherche de similarité haute performance.
Voir https://docs.cloud.google.com/vertex-ai/generative-ai/docs/rag-engine/vector-db-choices
On va juste rester sur le choix par défaut RagManagedDb.
Creation
import vertexai
from vertexai.preview import rag
PROJECT_ID = "..."
LOCATION = "europe-west9"
vertexai.init(project=PROJECT_ID, location=LOCATION)
GCS_BUCKET_NAME = f"{PROJECT_ID}-vertex-ai-rag"
GCS_BUCKET_FULL_PATH = f"gs://{GCS_BUCKET_NAME}"
RAG_NAME = "vertex-ai-code-rag"
embeddings_model = rag.RagEmbeddingModelConfig(
vertex_prediction_endpoint=rag.VertexPredictionEndpoint(
model="text-embedding-005",
),
)
rag_corpus = rag.create_corpus(
display_name=RAG_NAME,
backend_config=rag.RagVectorDbConfig(
rag_embedding_model_config=embeddings_model,
)
)
Ingestion
rag.import_files(
rag_corpus.name,
[f"{GCS_BUCKET_FULL_PATH}"],
transformation_config=rag.TransformationConfig(
chunking_config=rag.ChunkingConfig(
chunk_size=1024,
chunk_overlap=**256**,
),
),
)
Le resultat resemble a
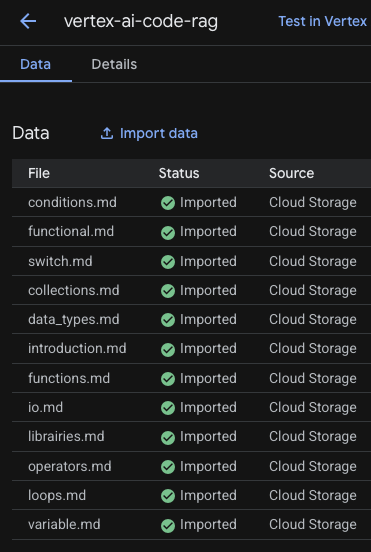
Etape 5: Recuperation
Comme preciser au dessus, il est assez simple de récupérer les infos depuis RAG Engine.
from vertexai.preview.generative_models import GenerativeModel, Tool
rag_retrieval_config = rag.RagRetrievalConfig(
top_k=10,
filter=rag.Filter(vector_distance_threshold=0.5),
)
response = rag.retrieval_query(
rag_resources=[
rag.RagResource(
rag_corpus=rag_corpus.name,
)
],
text="How to do a loop in Dart ?",
rag_retrieval_config=rag_retrieval_config,
)
print(response)
Le resultat ressemble a
contexts {
contexts {
source_uri: "gs://...-vertex-ai-rag/base/loops.md"
text: "Elle est fausse (4 n\'est pas inferieur ou égale à 3) donc l’instruction **for** se termine .\n\nBoucle for..in\nil existe aussi une boucle **for .. in** en Dart. Elle permet de faire une itération dans une collection **liste, ensemble ou dictionnaire**. la boucle **for .. in** est une boucle de parcours . C\'est à dire que la boucle est exécutée sur chacun des éléments d\'une collection.\n```dart\nvar langues = [\'Francais\', \'Anglais\', \'Espagnol\'];\nfor (var l in langues){\n print(l);\n}\n/* Output\nFrancais\nAnglais\nEspagnol\n*/\n```\nCette boucle se traduit par **pour l dans langues afficher l** .\n> Nous y reviendrons quand nous parlerons des collections en profondeur.\n\nBoucle while\nLe mot while se traduit par **tant que**. Alors cette boucle s\' exécute **tant que sa condition est vraie**.\nLa boucle while est une boucle à pré-condition. Cela veut dire que la condition est évaluée avant l\' exécution de l\'expression.\n!condition if/else/if\nSyntaxe d\'une boucle **while**.\n```dart\nwhile (condition) {\n portion de code;\n}\n```\n> Dans certain cas, une boucle while a besoin d\'une itération dans le corps de la boucle. L\' itération dans une boucle while est très importante car elle permet d\' arrêter la boucle à un moment donné.\n```dart\nint x = 1;\nwhile (x != 5){\n print(x);\n x++;\n}\nprint(\"La valeur final de x est $x\");\n/* Output\n1\n2\n3\n4\nLa valeur final de x est 5\n*/\n```\nDans ce cas , tant que x est différent de 5, les instructions de la boucle sont exécutées. Mais quand x est égal à 5 grâce à l\' incrémentation, la boucle se termine et le programme continue."
distance: 0.23738902056111
source_display_name: "loops.md"
score: 0.23738902056111
chunk {
text: "Elle est fausse (4 n\'est pas inferieur ou égale à 3) donc l’instruction **for** se termine .\n\nBoucle for..in\nil existe aussi une boucle **for .. in** en Dart. Elle permet de faire une itération dans une collection **liste, ensemble ou dictionnaire**. la boucle **for .. in** est une boucle de parcours . C\'est à dire que la boucle est exécutée sur chacun des éléments d\'une collection.\n```dart\nvar langues = [\'Francais\', \'Anglais\', \'Espagnol\'];\nfor (var l in langues){\n print(l);\n}\n/* Output\nFrancais\nAnglais\nEspagnol\n*/\n```\nCette boucle se traduit par **pour l dans langues afficher l** .\n> Nous y reviendrons quand nous parlerons des collections en profondeur.\n\nBoucle while\nLe mot while se traduit par **tant que**. Alors cette boucle s\' exécute **tant que sa condition est vraie**.\nLa boucle while est une boucle à pré-condition. Cela veut dire que la condition est évaluée avant l\' exécution de l\'expression.\n!condition if/else/if\nSyntaxe d\'une boucle **while**.\n```dart\nwhile (condition) {\n portion de code;\n}\n```\n> Dans certain cas, une boucle while a besoin d\'une itération dans le corps de la boucle. L\' itération dans une boucle while est très importante car elle permet d\' arrêter la boucle à un moment donné.\n```dart\nint x = 1;\nwhile (x != 5){\n print(x);\n x++;\n}\nprint(\"La valeur final de x est $x\");\n/* Output\n1\n2\n3\n4\nLa valeur final de x est 5\n*/\n```\nDans ce cas , tant que x est différent de 5, les instructions de la boucle sont exécutées. Mais quand x est égal à 5 grâce à l\' incrémentation, la boucle se termine et le programme continue."
}
}
contexts {
source_uri: "gs://...-vertex-ai-rag/base/loops.md"
text: "Il permet d\'initialiser un compteur qui sera ensuite utilisé dans la boucle.\n- **condition** dit si l\'expression doit être exécutée. Si elle est vraie **true**, l\' expression est exécutée puis l\'**itération** est évaluée (s’il en existe une). Si la condition est omise elle est considérée comme vrai **true**. Si la condition est fausse **false** , l’instruction **for** se termine et le contrôle passe à l’instruction suivante du programme.\n- **itération** est une expression qui s\' exécute à chaque itération de la boucle après l\' exécution de la portion de code de la boucle. L\' itération est généralement une incrémention ou une décrémentation.\nExemple\n```dart\nfor (var compteur = 1; compteur <= 3 ; compteur++){\n print(\"la valeur du compteur est $compteur\");\n}\n/* Output\nla valeur du compteur est 1\nla valeur du compteur est 2\nla valeur du compteur est 3\n*/\n```\nVoici comment la boucle for marche dans notre exemple.\nPour commencer l\'initialisation **var compteur = 1** est faite. Puis la condition est évaluée. Dans la première itération le compteur étant égal à 1 cette condition est vraie donc l\'expression dans la boucle est exécutée avec **compteur = 1**. Ensuite le programme passe à l\' itération qui incrémente la valeur du compteur à 2. La condition est encore évaluée. Avec le compteur étant égale à 2 cette condition est vraie donc l\'expression dans la boucle est exécutée avec **compteur = 2** et ainsi de suite. Quand le compteur arrive à 4, la condition est évaluée. Elle est fausse (4 n\'est pas inferieur ou égale à 3) donc l’instruction **for** se termine .\n\nBoucle for..in\nil existe aussi une boucle **for .. in** en Dart."
distance: 0.24335406368253987
source_display_name: "loops.md"
score: 0.24335406368253987
chunk {
text: "Il permet d\'initialiser un compteur qui sera ensuite utilisé dans la boucle.\n- **condition** dit si l\'expression doit être exécutée. Si elle est vraie **true**, l\' expression est exécutée puis l\'**itération** est évaluée (s’il en existe une). Si la condition est omise elle est considérée comme vrai **true**. Si la condition est fausse **false** , l’instruction **for** se termine et le contrôle passe à l’instruction suivante du programme.\n- **itération** est une expression qui s\' exécute à chaque itération de la boucle après l\' exécution de la portion de code de la boucle. L\' itération est généralement une incrémention ou une décrémentation.\nExemple\n```dart\nfor (var compteur = 1; compteur <= 3 ; compteur++){\n print(\"la valeur du compteur est $compteur\");\n}\n/* Output\nla valeur du compteur est 1\nla valeur du compteur est 2\nla valeur du compteur est 3\n*/\n```\nVoici comment la boucle for marche dans notre exemple.\nPour commencer l\'initialisation **var compteur = 1** est faite. Puis la condition est évaluée. Dans la première itération le compteur étant égal à 1 cette condition est vraie donc l\'expression dans la boucle est exécutée avec **compteur = 1**. Ensuite le programme passe à l\' itération qui incrémente la valeur du compteur à 2. La condition est encore évaluée. Avec le compteur étant égale à 2 cette condition est vraie donc l\'expression dans la boucle est exécutée avec **compteur = 2** et ainsi de suite. Quand le compteur arrive à 4, la condition est évaluée. Elle est fausse (4 n\'est pas inferieur ou égale à 3) donc l’instruction **for** se termine .\n\nBoucle for..in\nil existe aussi une boucle **for .. in** en Dart."
}
}
contexts {
source_uri: "gs://...-vertex-ai-rag/base/loops.md"
text: "title: Dart 05 - Les boucles\ndescription: Notion de boucle for, while et do while. Utilisation de break et continue\ntags: [dart, dart-base]\ntopics: [dart]\ndate: 2020-01-05\nslug: dart-05-les-boucles\nprev: dart-04-les-conditions\n\nnext: dart-06-switch-case\nUne boucle est une structure de contrôle destinée à exécuter une portion de code plusieurs fois de suite.\nIl existe plusieurs façons de créer une boucle. Quelle que soit la façon dont la boucle est créée, son but principal sera de répéter une portion de code ou une expression un certain nombre donné de fois. Il est préférable qu\'une boucle soit finie c\'est-à-dire que son exécution s\'arrête à un moment donné. On peut aussi avoir des boucles qui s\' exécutent à l\'infini.\nLe fonctionnement des boucles est assez simple. Elles exécutent la l\'expression quand la condition est vraie et s\' arrêtent quand la condition est fausse.\nIl existe plusieurs type de boucles.\n- for\n- while\n- do .... while\n> Les boucles peuvent être imbriquées\n\nBoucle for\nComme toutes les boucles, la boucle **for** permet de répéter une expression un certain nombre de fois.\nLa boucle **for** est une boucle à pré-condition. Cela veut dire la condition est évaluée avant l\' exécution de l\'expression. Si cette condition est vraie, la portion de code est exécutée sinon toute la boucle est terminée et le programme continue.\nSyntaxe pour écrire une boucle **for**.\n```dart\nfor (initialisation, condition, itération ){\n expression\n}\n```\nExplication\n!condition if/else/if\n- **initialisation** spécifie l\'initialisation de la boucle. Il permet d\'initialiser un compteur qui sera ensuite utilisé dans la boucle.\n- **condition** dit si l\'expression doit être exécutée."
distance: 0.25093429960754476
source_display_name: "loops.md"
score: 0.25093429960754476
chunk {
text: "title: Dart 05 - Les boucles\ndescription: Notion de boucle for, while et do while. Utilisation de break et continue\ntags: [dart, dart-base]\ntopics: [dart]\ndate: 2020-01-05\nslug: dart-05-les-boucles\nprev: dart-04-les-conditions\n\nnext: dart-06-switch-case\nUne boucle est une structure de contrôle destinée à exécuter une portion de code plusieurs fois de suite.\nIl existe plusieurs façons de créer une boucle. Quelle que soit la façon dont la boucle est créée, son but principal sera de répéter une portion de code ou une expression un certain nombre donné de fois. Il est préférable qu\'une boucle soit finie c\'est-à-dire que son exécution s\'arrête à un moment donné. On peut aussi avoir des boucles qui s\' exécutent à l\'infini.\nLe fonctionnement des boucles est assez simple. Elles exécutent la l\'expression quand la condition est vraie et s\' arrêtent quand la condition est fausse.\nIl existe plusieurs type de boucles.\n- for\n- while\n- do .... while\n> Les boucles peuvent être imbriquées\n\nBoucle for\nComme toutes les boucles, la boucle **for** permet de répéter une expression un certain nombre de fois.\nLa boucle **for** est une boucle à pré-condition. Cela veut dire la condition est évaluée avant l\' exécution de l\'expression. Si cette condition est vraie, la portion de code est exécutée sinon toute la boucle est terminée et le programme continue.\nSyntaxe pour écrire une boucle **for**.\n```dart\nfor (initialisation, condition, itération ){\n expression\n}\n```\nExplication\n!condition if/else/if\n- **initialisation** spécifie l\'initialisation de la boucle. Il permet d\'initialiser un compteur qui sera ensuite utilisé dans la boucle.\n- **condition** dit si l\'expression doit être exécutée."
}
}
}
On peut trouver dans le résultat la source, le texte en question, le score de confiance, le chunk source.
Utilisation
On peut alors partir d'ici pour avoir des tools qui peuvent être utilisés par notre agent IA (avec ADK par exemple) pour récupérer les infos intéressantes dans la database vectorielle via RAG.
import vertexai
from google.adk.agents import Agent
from vertexai.preview import rag
PROJECT_ID = "..."
LOCATION = "europe-west9"
vertexai.init(project=PROJECT_ID, location=LOCATION)
rag_retrieval_config = rag.RagRetrievalConfig(
top_k=10,
filter=rag.Filter(vector_distance_threshold=0.5),
)
rag_corpus = rag.get_corpus(name="projects/.../locations/europe-west9/ragCorpora/...")
def search_from_rag(query: str):
"""Searches the RAG corpus for relevant information based on the query.
Args:
query (str): The input query for which to search the RAG corpus.
"""
response = rag.retrieval_query(
rag_resources=[
rag.RagResource(
rag_corpus=rag_corpus.name,
)
],
text=query,
rag_retrieval_config=rag_retrieval_config,
)
return [ctx.text for ctx in response.contexts.contexts]
root_agent = Agent(
model="gemini-3.1-flash-lite-preview",
name="rag_engine_test",
instruction="""You are a helpful assistant.""",
tools=[
search_from_rag
],
)
Avantages et inconvénients
Bon, après avoir mis les mains dedans, voilà ce que j'en retiens.
Avantages
- Zéro infrastructure à gérer. C'est le gros point fort. Pas de base de données à provisionner, pas de cluster à maintenir, pas de mise à jour à gérer. On ingère, on interroge, c'est tout.
- Simple à prendre en main. La courbe d'apprentissage est vraiment faible. Le chunking, l'embedding, l'indexation. Tout est géré automatiquement.
- Plusieurs sources de données supportées. GCS, Google Drive, Slack... on peut alimenter le corpus depuis différents endroits sans pipeline custom.
Inconvénients
- Pas de recherche par métadonnées. C'est le point bloquant le plus frustrant. Impossible de filtrer les résultats sur des métadonnées custom (nom de fichier, version, type de document, projet...). La recherche se fait uniquement par similarité vectorielle. Si tu as un corpus hétérogène et que tu veux cibler un sous-ensemble précis de documents au moment de la requête, tu es bloqué.
- Peu de contrôle sur l'indexation. On peut ajuster le chunking, mais on reste limité sur la façon dont les documents sont traités. Pas de pipeline d'ingestion custom.
- Vendor lock-in. C'est du fully managed Google Cloud. Difficile de migrer vers une autre solution sans retravailler l'ingestion et les requêtes.
- Debugging limité. Quand les résultats sont mauvais, c'est compliqué de comprendre pourquoi. Peu de visibilité sur ce qui se passe à l'intérieur.
Dans la prochaine partie, nous allons voir Vector Search et ce que j'ai pu faire avec.